심리학 한글 글자 지각 - 한글은 어떻게 보이는가?
페이지 정보

본문

한글은 쉽게 파악하고 쉽게 배울 수 있다. 한글이 매우 과학적인 문자라는 것은 자타가 인정하고 있지만, 계속 살펴보고 개선할 여지가 있다. 이 글에서는 한글 글자가 어떤 시각적 특징을 가지고 있는지, 이와 관련된 논제가 무엇인지를 생각해 보자.
훈민정음 해례 <출처: wikipedia>
글자 상자 속에 옹기종기 모여 있는 낱자들
표1. 한글 글자의 여섯 유형 예시와 사용비율
한글 낱자들은 네모 모양의 글자로 모아져서 사용된다. 낱자들을 모아서 글자를 만들게 된 데에는 세종대왕과 집현전 학자들이 한자로부터 영감을 받은 바가 있을 것이다.
한자와 달리, 한글의 초성(첫 자음자)과 중성(모음자), 그리고 종성(받침)은 일정한 규칙대로 글자 안에 배치된다.
그리고 한 음절이 한 글자로 표시되기 때문에 한글을 읽을 때에는 단어를 음절 단위로 떼어서 읽어야 하는 문제가 거의 없다. 반면 로마자에서는 문자들이 일렬로 배치되므로 음절 간의 경계가 시각적으로 분명하지 않다.
연구자들은 한글 글자의 모양을 여러 가지로 나누었다(표 1). 즉 ‘ㅏ’나 ‘ㅓ’와 같이 긴 수직 막대를 가지고 있는 종 모음, ‘ㅗ’나 ‘ㅜ’와 같이 긴 수평 막대를 가지고 있는 횡 모음, 그리고 ‘ㅘ’나 ‘ㅝ’와 같이 두 가지가 합쳐진 종횡 모음을 구분하고, 여기에 받침의 유무에 따라 두 가지를 구별하였다.
표 1을 보면1), 종모음 글자가 62.7%로 전체적으로 가장 많이 쓰이고, 횡모음 글자는 30.9% 쓰이며, 종횡 모음이 쓰이는 비율은 6.3%에 불과하다. 글자 유형에 따라 글자와 낱자의 지각이 달라질 수 있음을 연구들은 보여준다.
- 이 비율은 김흥규와 강범모(1997)의 자료를 바탕으로 하였다. 사용 비율(상대빈도)은 세월이 흘러도 잘 변하지 않는다.
한글 낱자들은 네모 모양의 글자로 모아져서 사용된다. 낱자들을 모아서 글자를 만들게 된 데에는 세종대왕과 집현전 학자들이 한자로부터 영감을 받은 바가 있을 것이다. <출처: Wikipedia>
한글 글자들이 네모 상자 모양이기 때문에 생기는 문제점이 있다. 바로 글자 모양(윤곽)으로 글자들이 잘 구별되지 않는다는 것이다.
영어에서 ‘base’와 ‘vase’, 그리고 ‘face’와 ‘pace’ 쌍은 발음이 비슷하지만 글자 윤곽은 서로 다르다. 이런 정보는 단어 읽기에 큰 도움을 준다.
현재 우리가 주로 쓰는 한글 글자 모양은 서로 비슷하기 때문에 이런 정보를 활용할 수 없다. (고딕체는 명조체보다 윤곽이 더 비슷하기 때문에 고딕체 문장을 읽기가 어렵다.)
또 비슷한 크기를 유지하려다 보니, 받침 있는 글자에서 낱자들은 작게 표시되어 낱자의 획이 잘 식별되지 않을 가능성이 높아진다.
그러면 윤곽을 살려서 ‘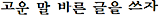 ’와 같이 받침을 아래로 빼면 어떨까? 네모 상자 글자꼴에 우리가 익숙하긴 하지만, 장기적으로 보면 이런 글자꼴이 효율적일 가능성이 있다.
’와 같이 받침을 아래로 빼면 어떨까? 네모 상자 글자꼴에 우리가 익숙하긴 하지만, 장기적으로 보면 이런 글자꼴이 효율적일 가능성이 있다.
끼리끼리 닮은 낱자들
한글 낱자들은 기본 형태로부터 나머지 형태들이 파생된다. 자음자에는 표 2와 같이 다섯 가지 기본형이 있고, 모음자에는 천(・), 지(ㅡ), 인(ㅣ)을 형상화했다는 세 가지 기본형이 있다.
기본형에 획을 더하면 다른 낱자가 되는데 이를 가획 원리라고 한다. 거꾸로 말하면 복잡한 낱자도 기본형으로 소급된다. 이 때문에 한글 자판은 융통성이 있다.
전화기에서는 글쇠(키)를 기본형 위주로 줄이고, 컴퓨터 자판에는 파생형까지 늘여 표시할 수 있다. 게다가 기본형과 파생형의 관계도 외우기 쉽다. 이런 점은 한자나 가나(日)는 물론, 영문자가 도저히 따라올 수 없는 장점이다.
표2. 한글 자음자의 기본형과 그 파생형
가획 원리의 다른 의미는 한글 글자에서 획 하나 하나가 중요하다는 것이다. 예컨대 ‘님’, ‘남’, ‘넘’은 작은 점(획)의 유무와 위치에 따라 서로 구별될 뿐이다.
낱자나 글자를 짧은 순간 비추어서(혹은 흐릿하게) 분명히 볼 수 없게 하면, ‘ㅋ’ 과 ‘ㄱ’, ‘ㄷ’ 과 ‘ㄴ’, ‘ㅑ’ 와 ‘ㅏ ’등과 같이 파생형과 기본형은 쉽게 혼동된다.
이들을 구별하려면 가획된 획들을 또렷이 보아야 한다. 그런데 받침이 있는 복잡한 글자의 경우 네모 상자에 낱자들이 꽉 들어차면, 획이 잘 보이지 않고 유사한 글자들과 혼동된다(예, ‘홀’ 과 ‘훌’, ‘윌’과 ‘월’). 여기에서 한글은 글자의 획을 정확하게 봐야 하는, 매우 분석적인 노력이 필요한 글자라는 것을 알 수 있다.2)
획을 정확히 봐야 한다는 점은 글자를 막 배우는 어린아이나 시력이 약해진 노인들에게는 매우 중요한 문제이다. 글자에서 중요한 획이 더 잘 보이는 글자꼴을 개발하는 데에도 관심을 가질 필요가 있다.
- 애매할 때 ‘훌로’가 아니라 ‘홀로’로 보기 쉽듯이, 문장이나 단어는 가능한 글자에 제한을 줌으로써 글자 식별의 부담을 줄여 준다. 그러나 이 때문에 오자를 찾아내기가 어렵다.
음소 문자, 혹은 음절 문자?
한글이 과학적인, 음소 문자라고들 하지만 우리는 좀처럼 음소 문자(알파벳) 단위로 한글을 쓰지 않는다. 예컨대 김 모 씨라고 하지, ‘ㄱ’ 씨라고 잘 하지 않는다.
알파벳이면서도 음절(즉, 글자)로 묶어서 표시하는 특성을 두고, 언어심리학자 Insup Taylor는 한글을 ‘알파벳식 음절 문자’라고 불렀다.
음절 단위로 표시하면 아무래도 군더더기가 붙는 경우가 많을 것이다. 반면에 장점도 있는 것 같다. 이런 점은 한글에서 쓰이는 글자 수를 조사해 보면 알 수 있다.
표3. 한글 음절의 초성(19개), 중성(21개), 종성(27개)에 쓰이는 자모들(총 67개)
표 3에서 보듯이 한글 초성에는 14개의 단자음과 5개의 쌍자음이 쓰이고, 중성에는 21개의 모음(복모음 포함)이 쓰이며, 받침에는 27개(쌍자음, 겹자음 포함)가 쓰인다.
그래서 초성과 중성만을 가진 글자의 최대 수는 19 x 21 = 399개이며, 받침이 있는 글자의 최대 수는 19 x 21 x 27 = 10,773개이다.
이 둘을 합친 11,172개가 한글에서 만들 수 있는 글자의 최대 수이다. 이 글자들이 모두 쓰이는 것이 아니라, 그 중 약 20%인 2,305개가 매체(책, 신문 등)에서 실제로 사용된 것으로 조사되었다(1997년).
그런데 우리가 읽는 모든 글자들의 99%는 단지 808개의 글자로 채워질 뿐이다(표 4). 중국에서 교양인이 쓰는 한자의 수는 (수준에 따라) 2~5만개가 된다고 하는데, 이와 비교하면 한글에서 쓰는 글자 수가 얼마나 적은지를 알 수 있다.
한글은 낱자 단위로 분석되면서도, 글자(음절) 단위로 파악될 수는 있는 양면성을 가지고 있다. <출처: corbis>
이 808개 글자 중, 받침이 없는 것은 211개이고, 받침이 있는 것은 597개이다. 받침 없는 글자가 전체 사용빈도의 약 54 %를 차지하며(표 1), 한 글자 기준으로 받침 있는 글자에 비해 평균 6.4배나 자주 사용된다.
그래서 약 200개의 받침 없는 글자(예, ‘가’)를 익히고, 여기에 받침이 붙는 몇 글자들을 이어서 외우면 대부분의 한글 글자를 쉽게 읽을 수 있다.3)
- 몇 개의 모음은 발음이 서로 잘 구별되지 않고, 음절의 끝소리는 일곱 가지(ㄱ, ㄴ, ㄷ, ㄹ, ㅁ, ㅂ, ㅇ) 중의 하나로 발음되므로, 99% 사용에 쓰이는 실제 음절(발음) 수는 800개보다 훨씬 더 적을 것이다.
표 4. 생성 가능한, 실제 사용되는, 그리고 흔히 쓰이는 글자의 수 (비율)
한글은 세계적으로 자랑할 만한 우수한 과학성을 가지고 있다. <출처: Mammique at fr.wikipedia>
그래서 한글을 읽기 위한 두 가지 방법이 있다. 첫째는 67개의 낱자를 배우고 이들을 결합하여 글자로 읽는 규칙을 배우는 방법이다. 둘째는 약 800개의 글자를 외우는 방법이다.
실용적으로 보면, 한글은 800여개로 이루어진 음절 문자(글자)로 볼 여지가 있다는 것이다. 한글은 낱자 단위로 분석되면서도, 글자(음절) 단위로 파악될 수는 있는 양면성을 가지고 있다.
이런 양면성은 한글 글자 지각의 융통성과 관련이 있을 것으로 생각된다. 한글 글자 지각에 대한 연구들을 보면, 한글은 경우에 따라서는 초성+중성의 결합체가 종성(받침)과 구분되어 지각되는 듯이 보이지만 간단한 글자의 경우(예, ‘간’)는 받침 있는 글자 전체가 한 덩어리로 지각되는 것처럼 보인다.
한국인의 문맹률은 세계적으로 낮은 수준이다. 한글이 읽기 쉽기 때문이다. 왜 한글은 읽기 쉬울까? 한글의 낱자(자모) 수가 얼마 되지 않고, 문자와 발음의 관계가 투명하니까(규칙적)!
그런데 로마자를 쓰지만, 한글처럼 문자-발음의 관계가 투명한 터키(어)의 문맹률은 우리보다 높다. 필자는 한글을 음절 단위로 모아 쓰는 것도 문맹률을 낮추는 한 원인이 되리라고 생각한다.
한글 음절들은 눈으로 잘 구별되고 사용하는 글자 수(약 800개)가 적은 편이어서, 시간을 들이면 글자를 통째로 배울 수 있는 여지가 있다.
만일 글자 내의 낱자와 음소(발음)를 대응시켜 읽기가 어렵다면, 글자를 통째로 외우는 대안(방법)이 있다! 즉 다른 언어와 비교해서, 여러 가지 길로 한글 글자를 익힐 수 있다.
한글의 과학성 그리고 미래
한글은 세계적으로 자랑할 만한 우수한 과학성을 가지고 있다. 하지만 현재의 한글이 궁극적이고 이상적인 것은 아닐 것이다.
한글은 네모 상자 모양을 유지하기 때문에 글자 윤곽 정보를 이용하지 못하고, 또 복잡한 글자 내에서 낱자들의 구별에 중요한 획의 탐지가 어려운 문제점이 있다.
반면에 글자로 모아 쓰기 때문에 음절의 구분이 용이한 이점도 있다. 요즘 소위 인터넷 초성체(예, ‘ㅋㅋ’)나 발음이 곤란한 글자가 쓰이곤 하는데, 이로 인해 미래에는 한글 글자 모양이나 용법이 바뀔 가능성도 있다.
한글의 과학성을 높이는 일에 꾸준한 관심을 가질 필요가 있다.
- 참고문헌
- 김흥규, 강범모 (1997). 한글 사용빈도의 분석. 서울: 고려대학교 민족문화연구소.
- C. Park (2009). Visual Processing of Hangul, the Korean Script. In Chungmin Lee, G. B. Simpson, Youngjin Kim (Eds.), The Handbook of East Asian Psycholinguistics, Vol. 3: Korean, Pp. 379-389.
- Cambridge UP.
- 김흥규, 강범모 (1997). 한글 사용빈도의 분석. 서울: 고려대학교 민족문화연구소.
- 글
- 박창호 | 전북대학교 심리학과 교수
- 서울대학교에서 박사학위를 받고, 현재 전북대학교 심리학과 교수로 있다. 공저로 인지심리학, 인지학습심리학, 인지공학심리학, 실험심리학용어사전 등이 있다.
주석
1
이 비율은 김흥규와 강범모(1997)의 자료를 바탕으로 하였다. 사용 비율(상대빈도)은 세월이 흘러도 잘 변하지 않는다.
2
애매할 때 ‘훌로’가 아니라 ‘홀로’로 보기 쉽듯이, 문장이나 단어는 가능한 글자에 제한을 줌으로써 글자 식별의 부담을 줄여 준다. 그러나 이 때문에 오자를 찾아내기가 어렵다.
3
몇 개의 모음은 발음이 서로 잘 구별되지 않고, 음절의 끝소리는 일곱 가지(ㄱ, ㄴ, ㄷ, ㄹ, ㅁ, ㅂ, ㅇ) 중의 하나로 발음되므로, 99% 사용에 쓰이는 실제 음절(발음) 수는 800개보다 훨씬 더 적을 것이다.
- 이전글당신의 에코지능은 몇 살? - 장바구니가 좋을까 종이봉투가 좋을까 16.02.06
- 다음글잠 잘 시간이 모자란 십대 - 4당 5락? 충분히 자야 공부도 잘한다. 16.02.06
댓글목록
등록된 댓글이 없습니다.